


新技術賦予空間智能 中大助機械人升級解難
- 普通話
- 廣東話
字號

- 超大
- 大
- 標準
- 小

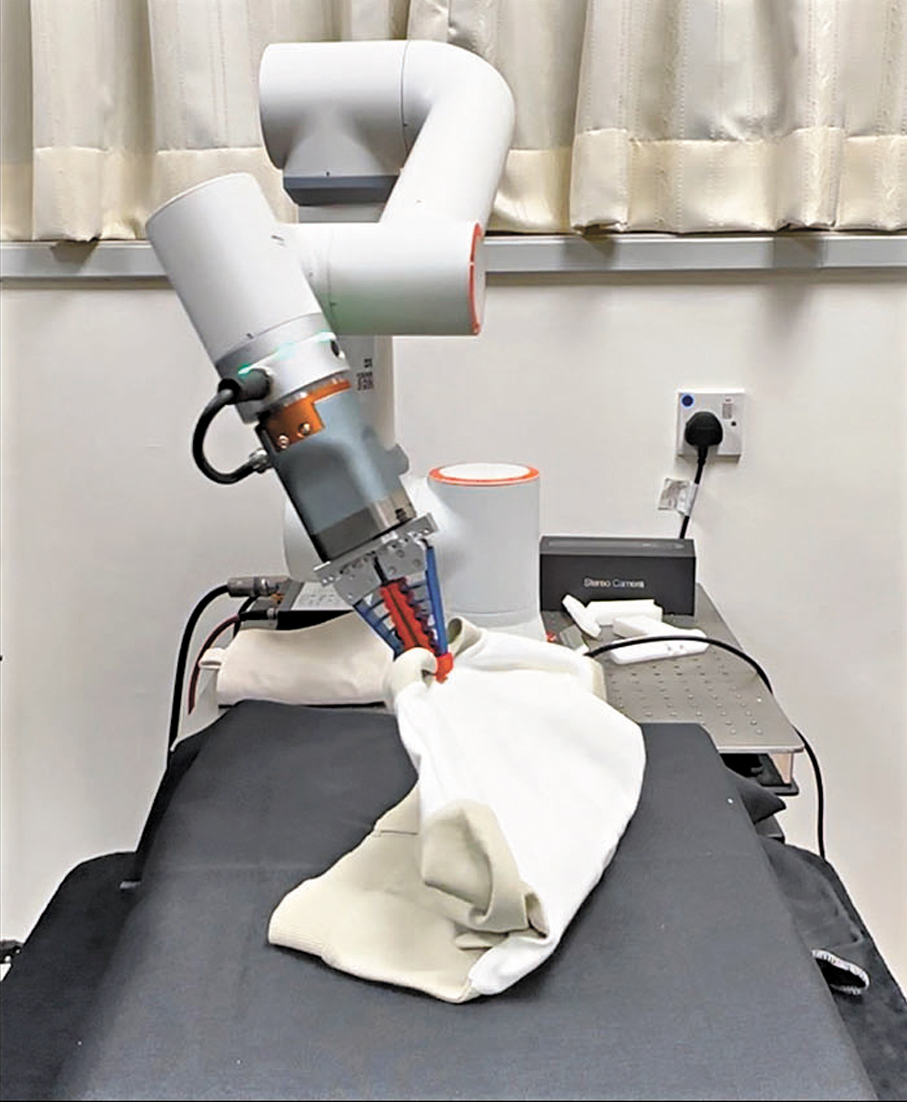
香港文匯報訊(記者 高鈺)香港中文大學工程學院團隊最近成功研發具空間智能的視覺語言大模型(Vision-Language Models,VLM)技術,讓機械人能像人類一樣理解三維空間資訊,具備可擴展的視觸融合能力,能自主完成涉及各類型物件的複雜長序列操作任務,進一步提升人工智能(AI)的分析能力。研究成果已於國際期刊《Science Robotics》上刊登。
可精確執行空間語言指令
現時的VLM雖然能讓機械人準確理解人類的語言指令,但它們對物體之間的三維空間關係缺乏深入認知,難以準確規劃長序列的操作任務,故中大團隊提出「檢索增強操作」的新方法,使機械人在規劃操作任務過程中能同時回答「每一步該做什麼」及「在三維空間中怎樣做才可行」兩個關鍵問題。
團隊為機械人建構了結構化的三維物件知識庫,記錄日常生活常見物件的三維幾何形狀、擺放方式及可抓取部位。VLM在生成操作計劃時,可即時從知識庫檢索物體的幾何與操作紀錄,評估操作可行性,以判斷實際可行的操作序列,並將抽象的指令轉化成準確的空間描述,賦予AI機械人執行複雜任務的能力。
負責研究的中大計算機科學與工程學系副教授竇琪表示,賦予機械人空間智能是提升機械人執行複雜操作能力的關鍵,視覺感知是實現空間智能的重要環節,是次研究在融合空間理解與大模型的推理方面實現了重大突破。
有關技術有廣泛的通用性和可擴展性,在目前涵蓋的31個不同物體的14項空間感知操作任務中,機械人可精確執行空間語言指令、推理三維空間關係,並根據場景物理條件作出自適應操作。新技術更可搭配現時市面通用的VLM使用,並可應用於通用的人形機械人平台操作任務。
 0
已點過讚
0
已點過讚
評論成功,請等待管理員審核...
評論(0)
0 / 255