


首次使用3D骨架 聲畫結合分析動作
- 普通話
- 廣東話
- 超大
- 大
- 標準
- 小
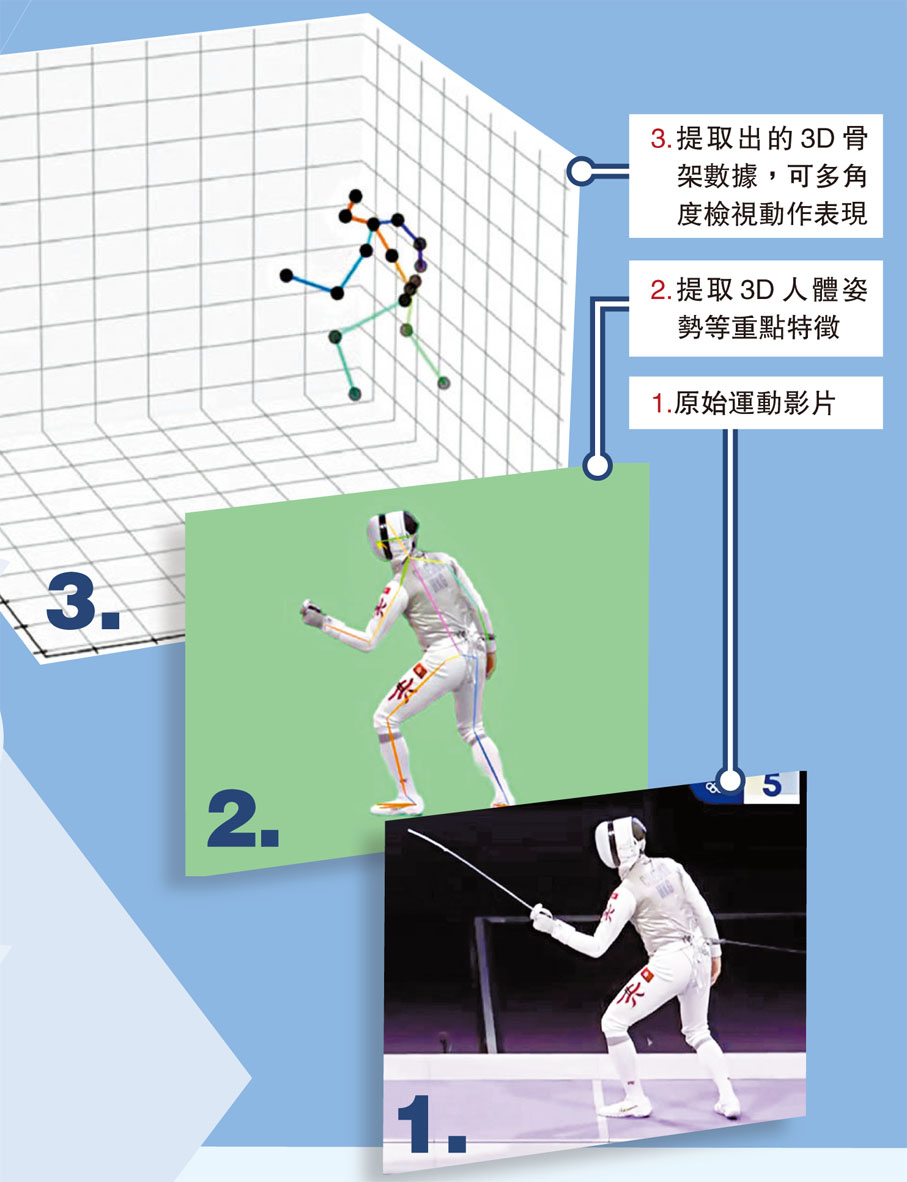
以視像影片技術為運動動作質量進行評估已發展相當長時間,不過過往技術主要基於視覺畫面或姿勢輸入,前者面對複雜的環境變數時,往往會忽略人類移動的重要詳情,後者則容易忽略場景中的細節,如跳水運動的水花;此外,傳統的2D關鍵點亦無法完全捕捉人體動作的細微之處。為解決這些缺點,梁永豪首次使用3D骨架方法(3D skeleton)作為特徵,結合三原色模式(RGB)及音頻特徵作多模態學習,令AI數據模型能力得以提高。
在項目的三年期內,平台初期會集中評估花樣滑冰及體操影片,其後會嘗試延伸到更多體育項目,期望發展出通用性強、可適用於多種運動和動作類型的人工智能體育評估平台。
「前人的研究大致可歸納為兩類,其中一類通常是從影片提取2D姿勢」,但梁永豪指,2D骨架缺乏深度訊息,在不同鏡頭角度的畫面下,即使運動員做相同動作,提取出來的2D姿勢特徵都會有些微差別,「人的動作始終都是3D的,2D難免有機會損失一些資訊。」因此其團隊首次使用3D骨架數據作為特徵,「好處是可以從多角度檢視動作表現,有更完整的空間訊息」,亦可減少對相機視角的依賴。
至於另一種方法是以視覺輸入,梁永豪解釋,這類方法會連運動員身後的背景都一併收錄,「當背景出現變化時,就未必可以將人和背景分得太清楚。」尤其部分藝術體操項目設有球、圈、絲帶、棒等關鍵道具,如當中球的軌跡,在這類方法下有機會被忽略。此外音頻訊息亦有其重要性,如花樣滑冰運動員能否根據音樂做出相應的動作,彼此是否匹配,都會影響最終得分。
「因此我們會結合以上的模態(Modality)去做機器學習,通過多模態學習,不同模態信息可以互補,提高模型能力。」他們會在運動影片中分別提取3D骨架、RGB及音頻特徵,其中3D骨架特徵經提取後,會再通過圖形卷積網絡(Graph Convolutional Network, GCN)模組處理,從而獲得更為自然流暢的3D人體姿勢信息,最終結合三者進行分析處理,得出影片評分。
梁永豪預計,項目會在首年建成系統,「第一年我們做的相對簡單,是一段段分開動作影片;第二年則會挑戰較長的運動影片,當中可能有很多不同的動作,系統如何逐一識別及分析,需要進一步嘗試。」至於第三年就會嘗試將系統通用至花樣滑冰及體操以外的運動項目,「如果可以通過微調已有系統,就能通用至不同運動項目,應用性就會更高。」
 0
已點過讚
0
已點過讚
評論(0)
0 / 255