


【智為未來】輸入數據要精確 才會得出好結果
- 普通話
- 廣東話
字號

- 超大
- 大
- 標準
- 小
上回(10月27日A21版)了解到數據偏差對AI數據訓練有什麼影響,今個星期就來講解一下有雜訊的數據又是如何影響AI模型訓練。
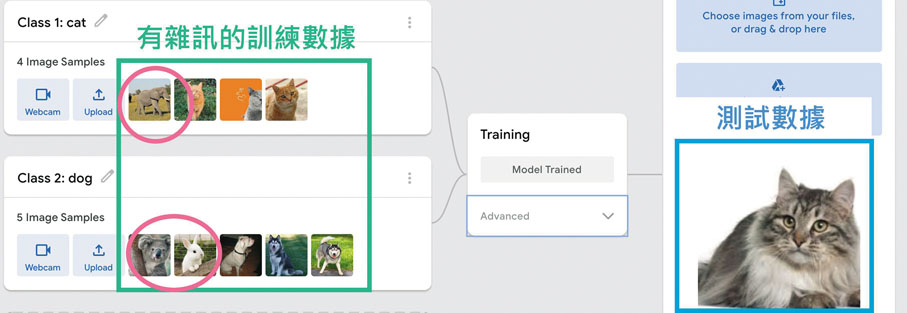
我們今日就以課程《第二課:人工智能基礎》的課堂活動三為例子。假如現在我們想訓練一個辨識出貓的AI模型,我們在訓練AI模型時,在大量貓的圖片數據中混入了其他動物(兔子和大象)的圖片,那麼AI模型最後能否正確辨識出貓的圖片呢?
答案是可以的。
在這個例子中,所加入的其他動物(兔子和大象)圖片就是有雜訊的數據。儘管測試結果能成功辨識出貓,但是這個AI模型的效能會受混有雜訊的訓練數據影響而下降,當使用兔子或大象的圖片時,這個AI模型就有可能出錯,辨識成貓。更嚴重的情況是無法進行判斷,因為混有雜訊的訓練數據會直接影響AI模型的學習閾值(threshold)。對訓練AI模型來說,混有雜訊的訓練數據是非常致命的。
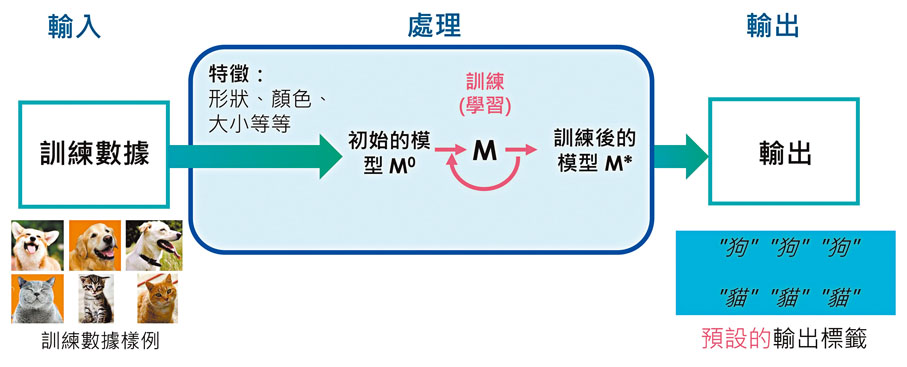
這兩個星期的例子都闡釋了AI數據輸入對AI模型訓練的重要性。上圖展示了AI模型訓練的輸入(Input)、處理(Process)和輸出(Output),簡稱IPO過程。要訓練出良好、準確的AI模型,所輸入數據的質量和代表程度對AI系統有關鍵的影響 ;決定數據質量的,就是數據的多樣性、準確性、是否有偏見、雜訊以及錯誤。假如我們輸入的數據質量「垃圾」(garbage in)的話,輸出的結果同樣會是「垃圾」(garbage out)。
● 中大賽馬會「智」為未來計劃
由香港賽馬會慈善信託基金捐助,香港中文大學工程學院及教育學院聯合主辦,旨在為香港中學創建新的AI課程、支援框架及可持續的AI教育模式,以促進相關的AI教育生態發展。嶄新又全面的AI課程希望為學生提供AI倫理意識和知識,裝備他們應對未來工作。
 0
已點過讚
0
已點過讚
評論成功,請等待管理員審核...
評論(0)
0 / 255