


【智為未來】數據有偏差 訓練會出錯
- 普通話
- 廣東話
- 超大
- 大
- 標準
- 小

人工智能(AI)依賴數據訓練以表現出人的智慧。機器會根據輸入的數據進行學習,所以數據的質素對所訓練的模型有極大的影響。當輸入數據出現問題時,所訓練的AI模型都會受到影響。數據的真實性、偏差、安全性和隱私都是常見的輸入數據問題。今日就跟大家分享一下,數據的偏差如何影響AI模型。
以下闡釋了由偏差數據訓練出來的兩個AI模型例子:
例子一:招聘中的性別偏見(公司AI招聘系統)
兩三年前,有跨國公司曾運用AI系統進行招聘及篩選申請者,系統使用過去十年的數據用作數據訓練。高科技行業在該段期間,男性申請者較多,而女性申請者的數據較少。所以數據庫選取會偏向選取男性,女性申請者分數會被降低,衍生出只選取男性申請者的惡性循環。為了減低數據的偏差,AI系統開發者應收集更多女性申請者的數據,來平衡兩性的數據再作數據訓練。
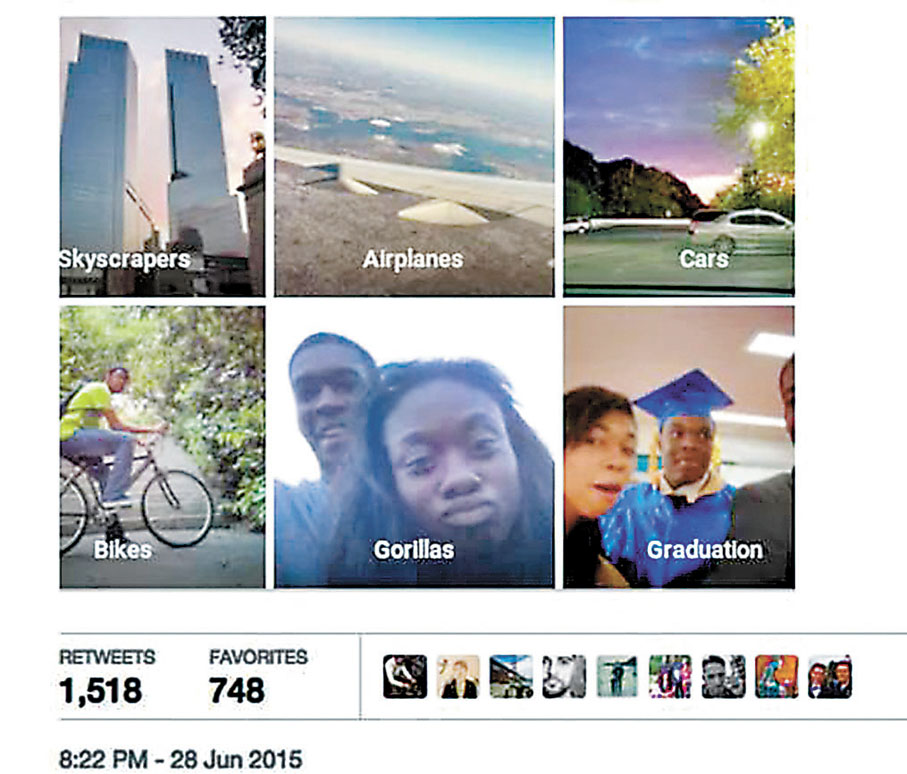
例子二:圖像識別中的種族偏見(圖片搜尋引擎)
在2015年,有網絡瀏覽器中的人臉識別程式,將兩名非裔人士錯誤地標記為「大猩猩」。雖然錯誤很快被修正,但許多人將錯誤歸咎於過度依賴白人的圖片進行AI數據訓練。
缺乏不同膚色人士的數據令演算法出現誤判,並得出明顯令人反感的結果。
透過以上例子,我們了解到數據偏差對AI數據訓練的影響,但如何可以改善或避免偏見?本計劃課程《第二課:人工智能基礎》運用多個本地和國際例子,令學生意識到AI技術中可能存在偏見,當設計AI系統和訓練數據時,要注意數據庫中的數據是否平衡,運用更公平的算法進行數據訓練,才能開發更好的AI模型。
● 中大賽馬會「智」為未來計劃
由香港賽馬會慈善信託基金捐助,香港中文大學工程學院及教育學院聯合主辦,旨在為香港中學創建新的AI課程、支援框架及可持續的AI教育模式,以促進相關的AI教育生態發展。嶄新又全面的AI課程希望為學生提供AI倫理意識和知識,裝備他們應對未來工作。
 0
已點過讚
0
已點過讚
評論(0)
0 / 255