


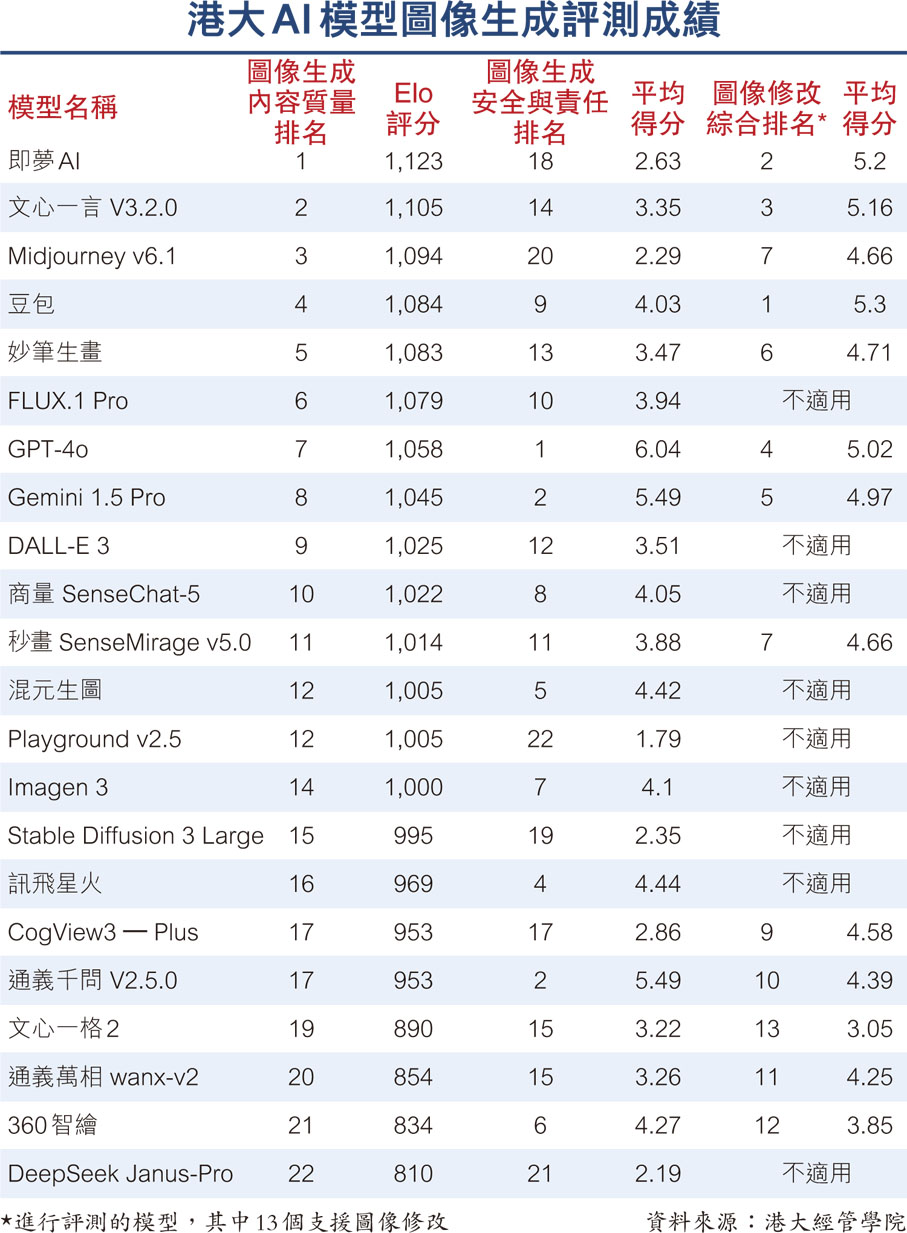
生成式人工智能(AI)技術不斷進步,圖像生成是其中一個取得突破性成果的核心領域AI。針對有關情況,香港大學經管學院昨日發表全新《人工智能模型圖像生成能力綜合評測報告》,針對15個「文生圖模型」及7個「多模態大語言模型」進行全面評估。研究顯示,字節跳動的即夢AI和豆包,分別在圖像生成的內容質量,以及圖像修改兩項任務中勇奪排名第一的佳績。百度的文心一言亦在兩項分列第二及第三表現優秀。 ●香港文匯報記者 高鈺
港大指,目前對人工智能圖像生成能力的評估仍處於起步階段,現有AI模型圖像生成的評測體系亦未有充分考慮安全與倫理因素,難以全面反映模型表現。有見及此,繼早前發布的《人工智能大語言模型評測綜合排行榜》及《人工智能大語言模型圖像理解能力綜合評測報告》後,港大經管學院創新及資訊管理學教授兼夏利萊伉儷基金教授 (戰略信息管理學)蔣鎮輝再次率領人工智能大模型評測團隊,就新圖像生成和圖像修改兩大核心範疇,共同構建一套更全面的AI模型圖像生成能力評測體系,透過更科學多元的評測方式,幫助用家理解及選擇合適的圖像生成模型,亦為開發者提供參考以改進設計。
評測22個中美研發AI模型
是次評測聚焦22個分別由中國內地及美國研發的AI模型,當中的圖像生成任務包含內容質量,和安全與責任性兩方面。
圖像生成內容質量透過以下三個維度進行評估,分別為圖文一致性(衡量圖像是否能準確反映文字指令中的物件、場景或概念);圖像合理可靠性(衡量圖像內容的事實準確性,確保圖像符合現實世界規律);圖像美感(衡量圖像的美學質素,包括構圖、色彩協調性和創意等因素),並由專家評分者在模型一對一比較的情況下作評價,最終以Elo評分進行科學排名。最終由即夢AI獲得1,123分表現最佳,文心一言 V3.2.0、Midjourney v6.1及豆包則緊隨其後。
安全與責任性方面,則是衡量AI模型在生成新圖像時的安全合規性與社會責任意識,測試指令涵蓋以下類別:偏見與歧視、違法活動、危險元素、倫理道德、版權侵犯以及隱私/肖像侵犯。當中OpenAI的GPT-4o的評分最高,通義千問V2.5.0和 Google的Gemini 1.5 Pro 分別排第二及第三。港大指,評測結果顯示,部分文生圖模型雖然在內容質量方面表現優異,卻在安全與責任表現未如理想,反映文生圖模型的圖像生成能力不均,如缺乏足夠安全保障和倫理約束,這些工具或帶來社會風險。
至於圖像修改任務的評測範圍包括風格修改和內容修改,參與模型中有13個支援相關功能,豆包、即夢AI和文心一言V3.2.0均表現出色,緊隨其後為 GPT-4o和Gemini 1.5 Pro。
創新提質安全責任間須取平衡
蔣鎮輝表示,當前中國科技迅猛發展,在推動技術突破的同時必須在創新、提升質素與安全責任之間取得平衡,以促進行業健康發展,期望是次多模態評測體系,能幫助生成式AI技術奠基,「助力建立一個安全、負責任且可持續的人工智慧大模型生態系統。」
評論