智為未來:大數據輸入系統 訓練模型測結果
之前的一連串文章,探究了AI如何應用於日常生活之中,相信大家已了解到AI是十分強大的,可以代替或幫助人類進行日常工作,甚至可以做到人類未必做到的事情。了解AI背後的原理可以提高我們運用AI科技的意識,有助我們於人機共存時代生活和工作。接下來,我們會跟大家講解AI模型是如何訓練的,以及AI的感知能力。
AI功能十分龐大,究竟AI模型是如何訓練的?相信大家對於運用搜尋引擎並不陌生,舉個例子,當我們想搜尋有關某部電影的資訊時,會使用搜尋引擎找尋我們希望得到的資訊。這個例子其實運用了「輸入(input)—處理(process)—輸出(output)」,簡稱「IPO」框架。我們會先輸入電影名稱,然後等待電腦回應並處理,最後得以輸出我們希望得到的資訊。
其實AI系統的IPO框架與上述操作十分相似,AI工程師會將巨量數據,亦即我們常聽到的大數據(big data)輸入至電腦系統,等待機器學習(machine learning)過程透過雲端計算(cloud computing)去完成,訓練後的模型便可以輸出用作預測結果。AI模型建基於數學演算法(algorithm),利用大量輸入數據來訓練,以模擬所作出的決策。
AI系統使用輸入數據訓練模型,再使用訓練後的模型來生成輸出。在訓練的過程中,AI模型會重複決策過程,從而實現自動化和理解。例如,輸入動物圖片作為數據,模型會根據形狀、顏色、大小和其他特徵,把每個輸入數據標籤為狗或貓。把初始模型經過訓練後,便成為了訓練後的模型。
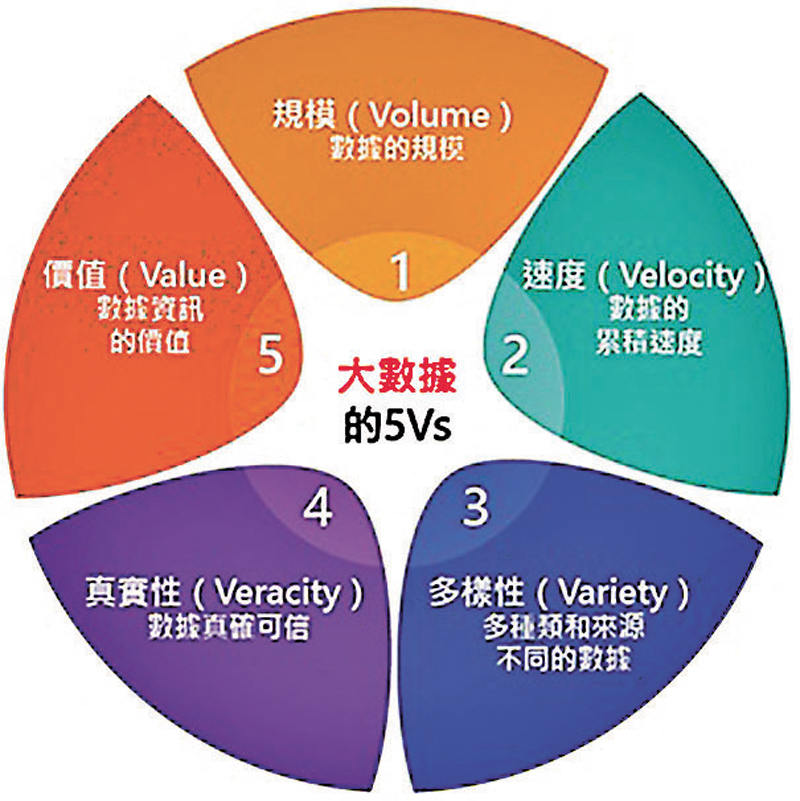
大數據具備五個特徵,包括:規模、速度、多樣性、真實性和價值。規模是指每日產生的巨量數據;速度是指數據的累積速度;多樣性是指多種類和來源不同的數據,例如圖像、影片、文本、語音和氣象數據等,同時亦需注意數據是否有所偏頗,即是輸入數據能否有效地代表整組數據集。例如,若我們想知道所有學生的成績分布,但卻只在系統輸入女生的分數,而不提供男生的分數,這樣就不能夠反映整體學生的成績分布。
真實性是指數據是否真確可信,並使系統中的輸入數據能保持原始狀態,與收集時的完全相同。所謂「無用輸入、無用輸出」,這個概念是指我們把錯誤或不可靠的數據輸入並經過電腦處理後,最終只會生成無用的輸出;價值是指收集的數據是否有用。這些都是我們需要考慮的重要因素,會影響到最終的成果。最後,倫理問題亦是重中之重,使用者需注意數據安全性,避免數據受到損壞或防止未經授權使用,亦要確保數據私隱受到保護,免遭未經授權的不當使用。
◆ 中大賽馬會「智」為未來計劃 https://cuhkjc-aiforfuture.hk/
由香港賽馬會慈善信託基金捐助,香港中文大學工程學院及教育學院聯合主辦,旨在透過建構可持續的AI教育生態系統將AI帶入主流教育。通過獨有且內容全面的AI課程、創新AI學習套件、建立教師網絡並提供AI教學增值,計劃將為香港的科技教育寫下新一頁。
