【智為未來】電腦識別口語 語音轉換成文本
除了上回提到的視覺,AI和人類一樣,也有聽覺。
相信大家也有用過智能手機AI助理,例如Apple Siri、Google Assistant和Amazon Alexa等,這些AI助理會把我們的語音輸入轉錄成文本,再根據文本內容來理解和執行指令,例如進行搜尋、打電話或控制家電等。今天,我們將探討當中的前半部分,即「語音轉文本」AI技術的運作原理。
自動語音識別(Automatic Speech Recognition,簡稱ASR)是一項常用的AI技術,能使電腦識別人類口語,將其翻譯成文本。當人們對麥克風(數碼設備)說話時,ASR便會將聲音從模擬訊號轉換為數碼訊號,使語音分割成幀(frame),並使用這些幀來建構狀態(status),再使用狀態來建構音位(聲學模型)。之後,ASR會將音位組合並建構為詞語(詞庫模型)。最後,語音便會轉換為文本(語言模型)。
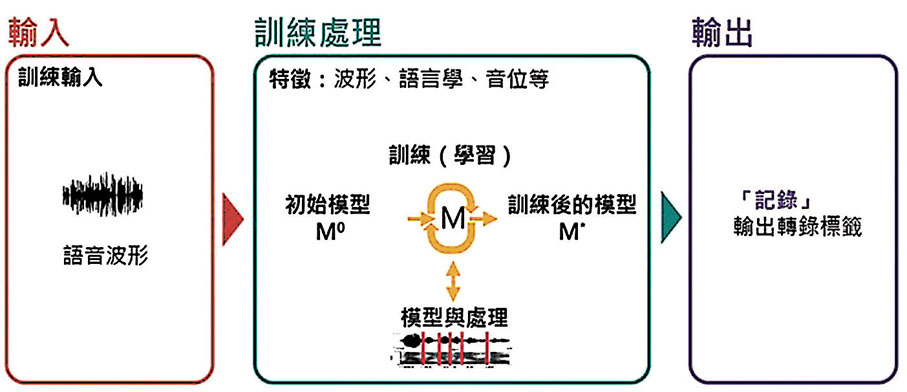
這項技術,涉及模型訓練和測試兩個過程,可以概括為「輸入—處理—輸出」的步驟。輸入語音後,ASR系統會提取特徵,然後放進模型內訓練和配對,最後再由系統輸出轉錄標籤。ASR系統的準確度,取決於用來訓練模型的數據量,因此系統需要大量訓練數據,才能製作出優質的模型。當模型訓練完成後,用戶可以透過語音測試模型,而經過訓練的語音識別器,便能準確地闡釋輸入語音,然後輸出轉錄標籤。
除了智能電話的AI助理外,ASR系統廣泛應用於我們的日常生活中,例如聽寫系統、電腦輔助語言學習系統、構音障礙語音識別器等。在一般的語音識別情況下,ASR已達到人類的水平,而某些ASR系統更聲稱在執行語音識別方面,也達到相同水平。
雖然現今的ASR技術已經相當成熟,但還是有其局限和挑戰。ASR的識別和轉錄準確度,受到多種因素所影響,例如語音的格式(即內容、說話者的特徵、口音等),以及背景噪音和錄音設備的質素等。
另外,在使用ASR的時候,我們也需要注意倫理相關的問題。先進的ASR需要大數據來訓練,但低資源語言(通常是指少數族群的語言,包括兒童、長者、殘疾人士,以及說話帶口音的人)的數據量十分稀少,所以要為少數族群提供良好的支援,是項重大的挑戰。
除此之外,在我們透過語音來溝通交流的時候,語音當中可能包含私人資訊。可是,無論我們是否正在向智能揚聲器或AI助理說話,它們也可能會一直記錄着你所說的話。因此,我們也需要注意自己所說的話,是否在未經同意的情況下被錄音。
◆ 中大賽馬會「智」為未來計劃 https://cuhkjc-aiforfuture.hk/
由香港賽馬會慈善信託基金捐助,香港中文大學工程學院及教育學院聯合主辦,旨在為香港中學創建新的AI課程、支援框架及可持續的AI教育模式,以促進相關的AI教育生態發展。嶄新又全面的AI課程希望為學生提供AI倫理意識和知識,裝備他們應對未來工作。
