【攜手共研】「擰走」冗餘資訊 速測基因數據

城大研發智能壓縮技術 夥內地科研機構助制定國家標準
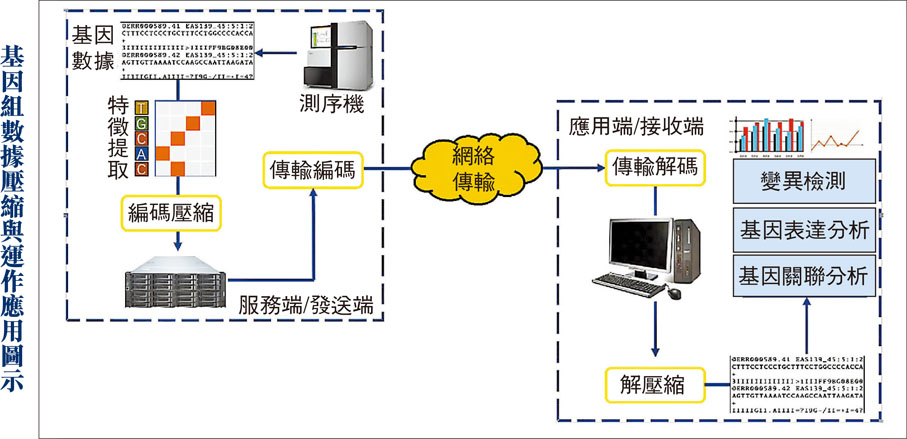
基因序列是生物醫學研究及應用中不可或缺的知識及信息,隨着測序技術的迅猛發展、測序時間及成本下降,基因測序需求的急速上升產生龐大的基因數據量,造成存儲和傳輸上的壓力。香港城市大學電腦科學系助理教授王詩淇及其團隊正研發智能高效壓縮技術,結合機器學習演算法,如同「擰毛巾」般將基因組數據的冗餘資訊「擰走」,減少數據量,從而提升基因組數據的利用效率,並與內地科研機構合作,制定基因組數據壓縮的國家標準。◆香港文匯報記者 鍾健文
基因測序數據量非常龐大,以人類基因組為例,人體DNA含有大約30億「鹼基對」。所謂「鹼基對」是形成核酸DNA單體以及編碼遺傳信息的化學結構,在DNA雙螺旋結構中,分別以A、C、G、T表達4種鹼基。
以1位元組存儲1個「鹼基對」,則會生成3GB的基因數據,而在測序過程中,往往需對序列進行多次測序,以保證測序的精準度,同時測序過程中會產生用於標記每個鹼基測序品質的「品質分數」,過程涉及很大的數據量。若能對基因數據進行有效的壓縮,則既可以大大降低存儲和傳輸所需要的時間和成本,又可以提高基因數據的使用效率。
AI深度學習 挖掘數據規律
王詩淇解釋,數據之所以能被壓縮,是因為當中存在冗餘,這意味着數據中的部分資訊能被其他的資訊所表示,例如人體基因的多次測序必然會在測序文件中引入重疊的序列,重疊的部分則不需要重複存儲。他以「擰毛巾」來比喻,「壓縮就是要把毛巾的水扭至最乾,消除冗餘資訊,讓數據量變得更小。」他和團隊利用近年興起的AI機器深度學習,從大量的數據中學習數據的統計特性,將規律從數據中挖掘出來,以便在做預測推理的時候發現冗餘資訊並將其消除,但又不影響數據的準確度和使用。
夥深圳鵬城實驗室研發
有關研究去年成為國家科技部與香港創新科技署「內地與香港聯合資助計劃」首批獲資助項目,其中香港的資助額逾250萬元,研究期至2023年3月;項目並由深圳鵬城實驗室擔任內地夥伴機構,以及獲基因產學研資聯盟支持及華大智造贊助。
研究主要分兩個階段,在第一階段主要側重於高效壓縮演算法的研究與開發,第二階段側重於高效傳輸演算法的開發。
王詩淇指,城大在壓縮方面的任務主要基於人工智慧技術,開發針對基因組序列特性的鹼基字典建模及壓縮演算法,「傳輸方面我們需要面向基因組數據最終應用場景,應用先進機器學習技術對數據傳輸過程進行優化,提升傳輸效率」;深圳鵬城實驗室方面需要開發針對測序文件中的品質分數的壓縮演算法,以及基因組數據安全高效傳輸演算法。
他表示,目前團隊已在基於機器學習的基因數據壓縮基礎技術方面取得一些成果,更有3個向內地數字音視頻編解碼技術標準工作組(AVS)提交的技術提案獲得採納,「有關技術方案考慮了複雜度和性能兩個方面,在應用落地方面都具備一定優勢」,不過如何從計算複雜度和壓縮效率中找到平衡點,使得技術能逐漸走向落地商用,是團隊需要攻克的難關。目前其團隊在對相關編解碼器進行優化,探索降低壓縮基因數據複雜度的方法;又與深圳鵬城實驗室合作開展第二階段數據傳輸的研究。
